Seed1.6-Embedding模型登顶多榜单SOTA
时间:2026-01-10 15:29:35
随着人工智能技术的快速进步,使机器深度理解世界的迫切需求变得前所未有的强烈。无论是电商平台中的跨模态搜索、智能助手的多轮交互,还是内容平台精准推送,其基础都依赖于一项核心能力将文本、图像和视频等各类信息形式转换为计算机可识别的“向量”。通过这些向量之间的关联,实现了高效的信息匹配与检索。
,火山引擎正式发布全模态向量化模型SeedEmbedding,凭借三大关键突破,在权威评测中包揽了中文文本和多模态任务的SOTA成绩,首次实现了“文本+图像+视频”多模态融合检索,并通过指令自定义功能显著降低了应用门槛。
从“单模态支持”迈向“全任务领先”:Seed1.6-Embedding的技术亮点
为了满足行业对于多模态深层理解与高效率检索的需求,研发团队采用了“文本继续训练 + 多模态继续训练精调” 的分阶段方法。依托海量的文本、图文对、视频文对数据,构建了多任务训练集,并结合指令引导、数据合成、增强以及分层负样本策略进行混合训练,显著提升了模型在细分场景和复杂任务下的表现力。最终,这款模型成为覆盖广泛场景的“全能型选手”,具备高效率检索和全面理解能力。
全面任务领先:中文文本、图像、视频三榜登顶
在最能体现模型泛化能力的权威榜单中,Seed1.6-Embedding展现出明显优势:
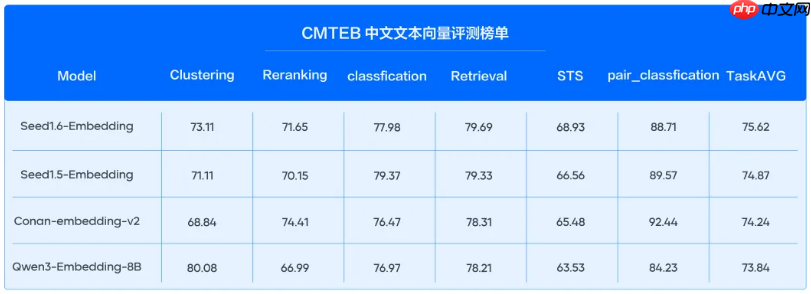
在CMTEB中文文本向量评测榜单上,我们的模型以高分打破纪录,持续领跑于检索、分类和语义匹配等通用任务。
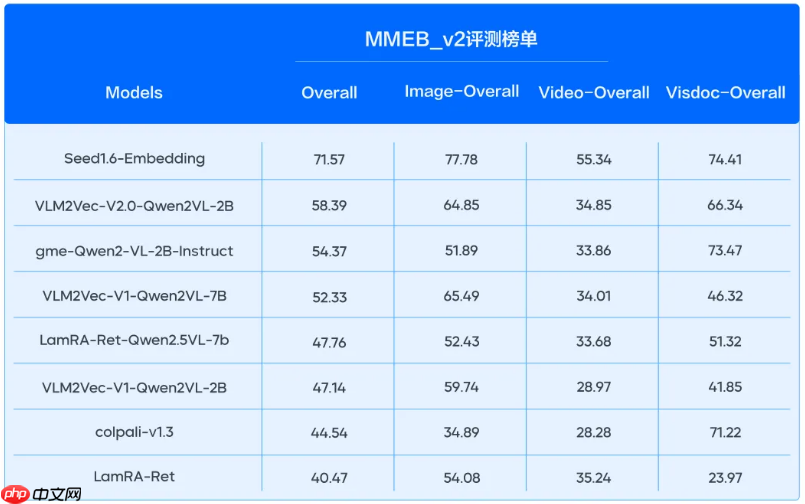
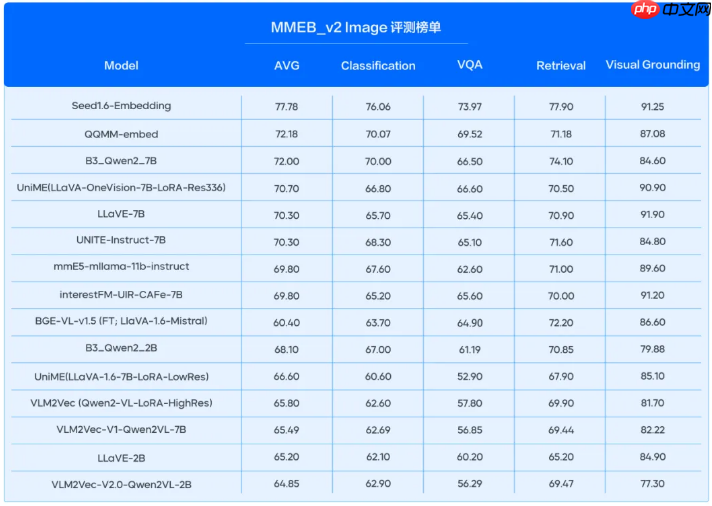
在多模态任务挑战中,我们展示了显著的进步。我们的模型在MMEB_v单上,在图片与视频向量化方面实现了突破性成就,得分领先于所有竞争对手,并且在新增的视频模态任务中,大幅超越了第二名的差距。这些成就展示了我们技术的强大能力和模型对新挑战的适应能力。
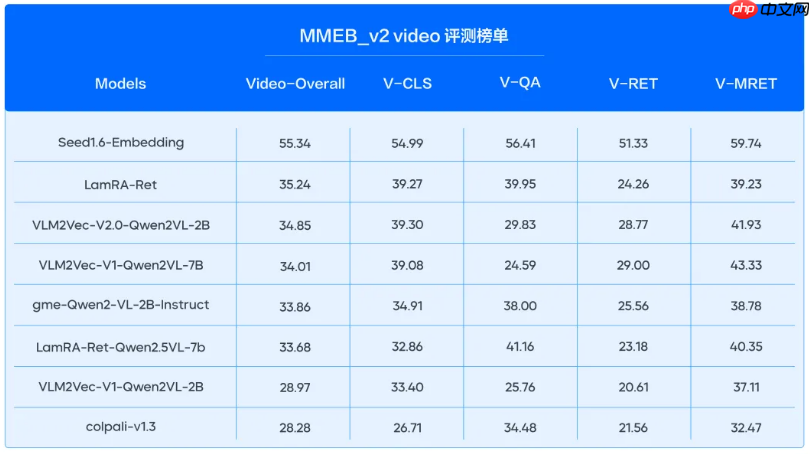

全模态混合检索:实现“文+图+视频”统一向量空间表达
SeedEmbedding解决了多模态向量化的局限性,使得用户能通过混合检索(如文字搜索图片、图像搜索视频)获得所需信息,从而大大提升了应用的灵活性和实用性。
新增视频向量化能力:能够对人物、动作、场景等视频核心语义进行统一表征;
探索全新多模态智能搜索技术:支持文本、图片、音频等多类型输入,并将这些信息转化为统一的矢量表示,以此展示每种模态的关键特性。这使用户能够轻松获取和比较不同形式的信息。这种能力不仅扩大了检索范围,还增强了理解和个性化体验。
指令定制增强:让向量生成“随需而动”
在实际业务中,向量的不同场景关注点各异。比如,电商更注重商品的价格和材质信息,而新闻平台则主要关注事件的时间节点与情感倾向。过往企业常需投入大量人力标注数据以微调模型,这不仅成本高且耗时长。随着技术进步,如今向量计算可以自动处理这些任务,大幅降低了人工标注的需求,显著提高了效率。
SeedEmbedding引入指令增强机制,使向量生成更具可控性:用户只需配置定制化指令模板,即可像下达任务清单一样引导向量表达更加贴合具体业务需求。这种能力让模型适配新场景从“重训练”变为“轻调整”,成本低且高效支撑电商推荐、知识问答等多种应用场景,实现一模型多用途,灵活响应变化。
从“技术创新”走向“场景落地”:火山方舟助力快速部署
- 为了加速SeedEmbedding的实际应用部署,我们同步推出了两种接入途径:便捷集成和灵活定制接口。
火山方舟API接口现已全面上线,让专业开发者能直接调用,无需自行建立模型训练及部署系统。只需在控制台上便捷操作,轻松将新功能融入业务流程中。
- VikingDB现在整合了SeedingEmbedding功能,实现从“向量生成到存储再到检索”的全面解决方案,使企业客户能无缝接入。
未来,团队将继续深耕向量化技术。预计下半年,在火山方舟体验中心,用户将能够实现可视化操作和多模态检索功能。VikingDB将支持全模态数据的自动向量化处理,并开源图文与视频检索项目,帮助企业和开发者快速集成到实际业务中。火山引擎将以更开放的姿态,携手合作伙伴共同探索“让AI理解世界”的无限可能。
以上就是Seed1.6-Embedding模型登顶多榜单SOTA的详细内容,更多请关注其它相关文章!