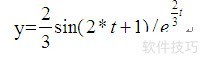一文搞懂Paddle2.0中的学习率
时间:2026-02-16 09:31:32
本项目聚焦于深度学习中的关键参数学习率(Learning Rate)。通过分析和对比使用Paddle供的默认学习率以及自定义的Cooling-learn-rate(CLR)和其他调整学习率策略(如线性热身)的效果,我们对这三种方法进行了深入测试。结果表明,自定义CLR方法表现最佳,而LinearWarmup策略同样具有潜力,值得进一步探索和尝试。我们将这些学习算法应用于蜜蜂黄蜂分类数据集上,验证了它们在实际应用中的适用性和性能提升空间。

1. 项目简介
深度学习中的学习率是一个关键参数,我们在项目中将从以下三个维度深入了解它: 掌握Paddle带的学习率API的使用指南: - 详细介绍如何在实际应用中正确调用这些API。 对比分析不同学习率策略的效果: - 评估并比较几种常见学习率方法的优势与不足,帮助你理解在何种条件下它们表现最佳。 探索自定义学习率算法的实现路径: - 尝试构建和应用自己设计的学习率方案,以复现Paddle目前没有的功能,进一步提升模型训练性能。
那么什么是学习率呢?
众所周知,深度学习的目标是找到适用于我们任务的函数,而要找到这个函数则需要确定其参数值。为达成此目的,我们需要首先设计一个损失函数(loss function),然后将我们的数据输入到待定参数的备选模型中,使损失函数在此过程中达到最小值。因此,这一调整过程即被称为“梯度下降”(gradient descent)。同时,我们可以通过设置学习率来控制参数值的调整幅度。从这可以看出,学习率是深度学习框架中的一个重要概念。幸运的是,Paddle提供了许多实用的学习率函数供开发者使用。本项目将深入探讨这些Paddle中的学习率函数,并研究如何自定义学习率函数以供参考与交流。对于希望自行设计学习率函数的朋友们来说,这也提供了一个宝贵的指南和资源。
2. 项目中用到的数据集
本项目采用的分类数据集涵盖了类别的昆虫,包含类别:蜜蜂、黄蜂、其他昆虫和无标注类型。共有图片,其中蜜蜂,黄蜂,其它昆虫,其余类别。
2.1 解压缩数据集
In []
!unzip -q data/data65386/beesAndwasps.zip -d work/dataset登录后复制
2.2 查看图片
In []
import osimport randomfrom matplotlib import pyplot as pltfrom PIL import Image imgs = [] paths = os.listdir('work/dataset')for path in paths: img_path = os.path.join('work/dataset', path) if os.path.isdir(img_path): img_paths = os.listdir(img_path) img = Image.open(os.path.join(img_path, random.choice(img_paths))) imgs.append((img, path)) f, ax = plt.subplots(2, 3, figsize=(12,12))for i, img in enumerate(imgs[:]): ax[i//3, i%3].imshow(img[0]) ax[i//3, i%3].axis('off') ax[i//3, i%3].set_title('label: %s' % img[1]) plt.show() plt.show()登录后复制
<Figure size 864x864 with 6 Axes>登录后复制
2.3 数据预处理
In []
!python code/preprocess.py登录后复制
finished data preprocessing登录后复制
3. Paddle2.0中自带的学习率
Paddle定义了不同的学习率算法,本项目将采用Momentum优化器进行性能比较。这些算法包括CosineAnnealingDecay、ExponentialDecay、InverseTimeDecay、LambdaDecay、LinearWarmup、LRScheduler、MultiStepDecay、NaturalExpDecay、NoamDecay、PiecewiseDecay、PolynomialDecay、ReduceOnPlateau和StageDecay。
3.1 使用余弦退火学习率
使用方法为:paddle.optimizer.lr.CosineAnnealingDecay(learning_rate, T_max, eta_min=0, last_epoch=- 1, verbose=False)
这差不多是最有名的学习率算法了。
更新公式如下: In [1]
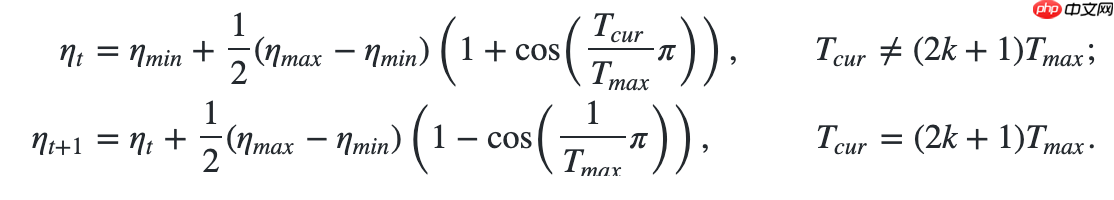
## 开始训练!python code/train.py --lr 'CosineAnnealingDecay'登录后复制
可视化结果
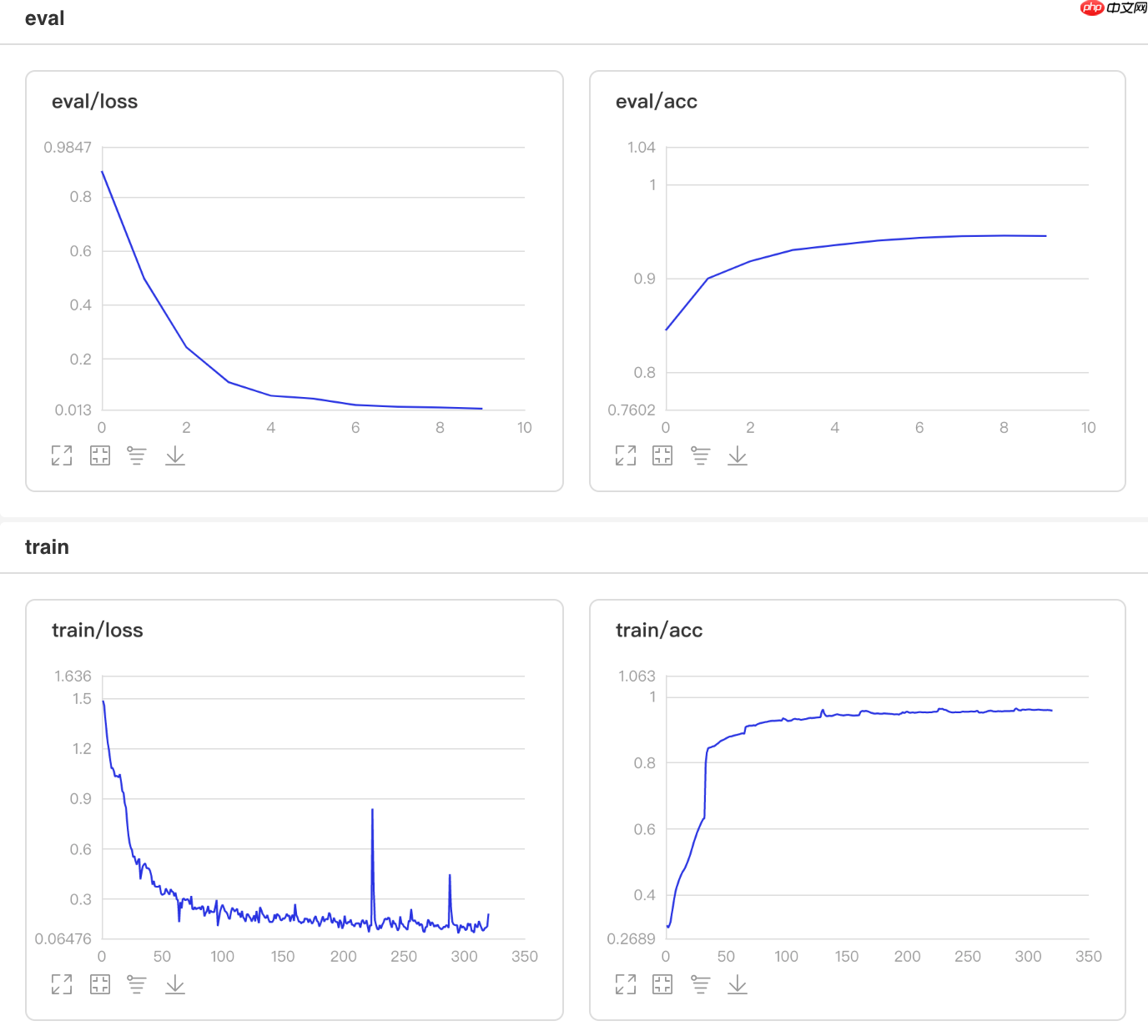
图1 CosineAnnealingDecay训练验证图 In [13]
## 查看测试集上的效果!python code/test.py --lr 'CosineAnnealingDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:14:08.330015 4460 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:14:08.335014 4460 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9472 - 734ms/step Eval samples: 1763登录后复制
3.2 使用指数衰减学习率
使用方法为:paddle.optimizer.lr.ExponentialDecay(learning_rate, gamma, last_epoch=-1, verbose=False)
该接口提供一种学习率按指数函数衰减的策略。
更新公式如下: In [2]
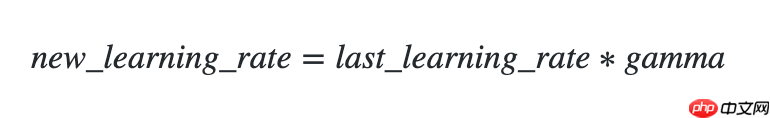
## 开始训练!python code/train.py --lr 'ExponentialDecay'登录后复制
可视化结果
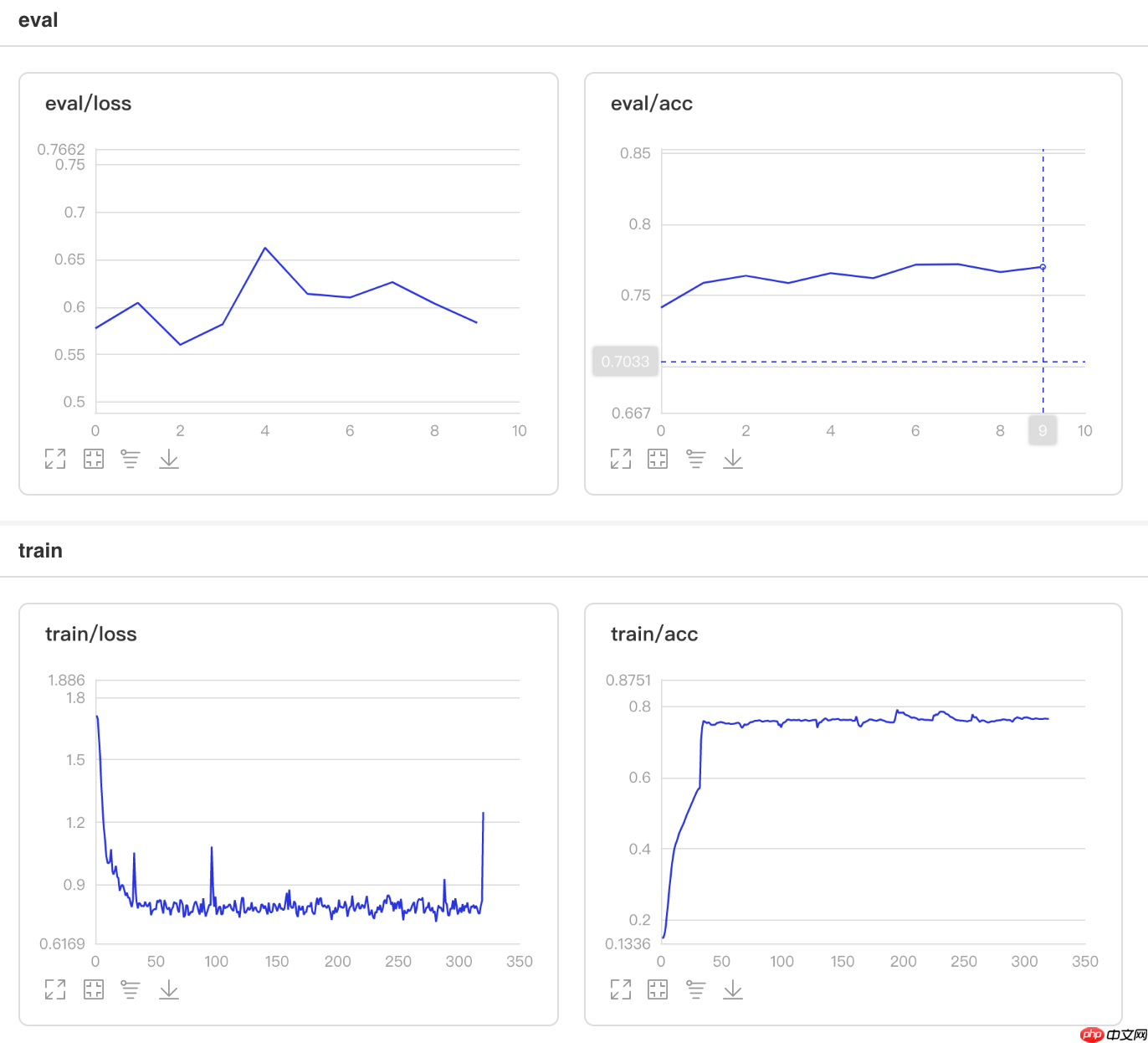
图2 ExponentialDecay训练验证图 In [12]
## 查看测试集上的效果!python code/test.py --lr 'ExponentialDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:11:58.334306 4184 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:11:58.339387 4184 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.7686 - 854ms/step Eval samples: 1763登录后复制
3.3 使用逆时间衰减学习率
使用方法为:paddle.optimizer.lr.InverseTimeDecay(learning_rate, gamma, last_epoch=- 1, verbose=False)
该接口提供逆时间衰减学习率的策略,即学习率与当前衰减次数成反比。
更新公式如下: In [3]
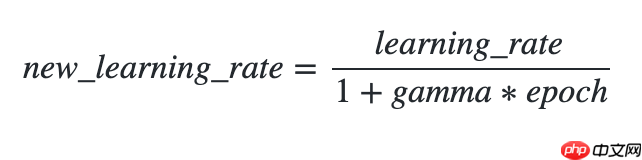
## 开始训练!python code/train.py --lr 'InverseTimeDecay'登录后复制
可视化结果
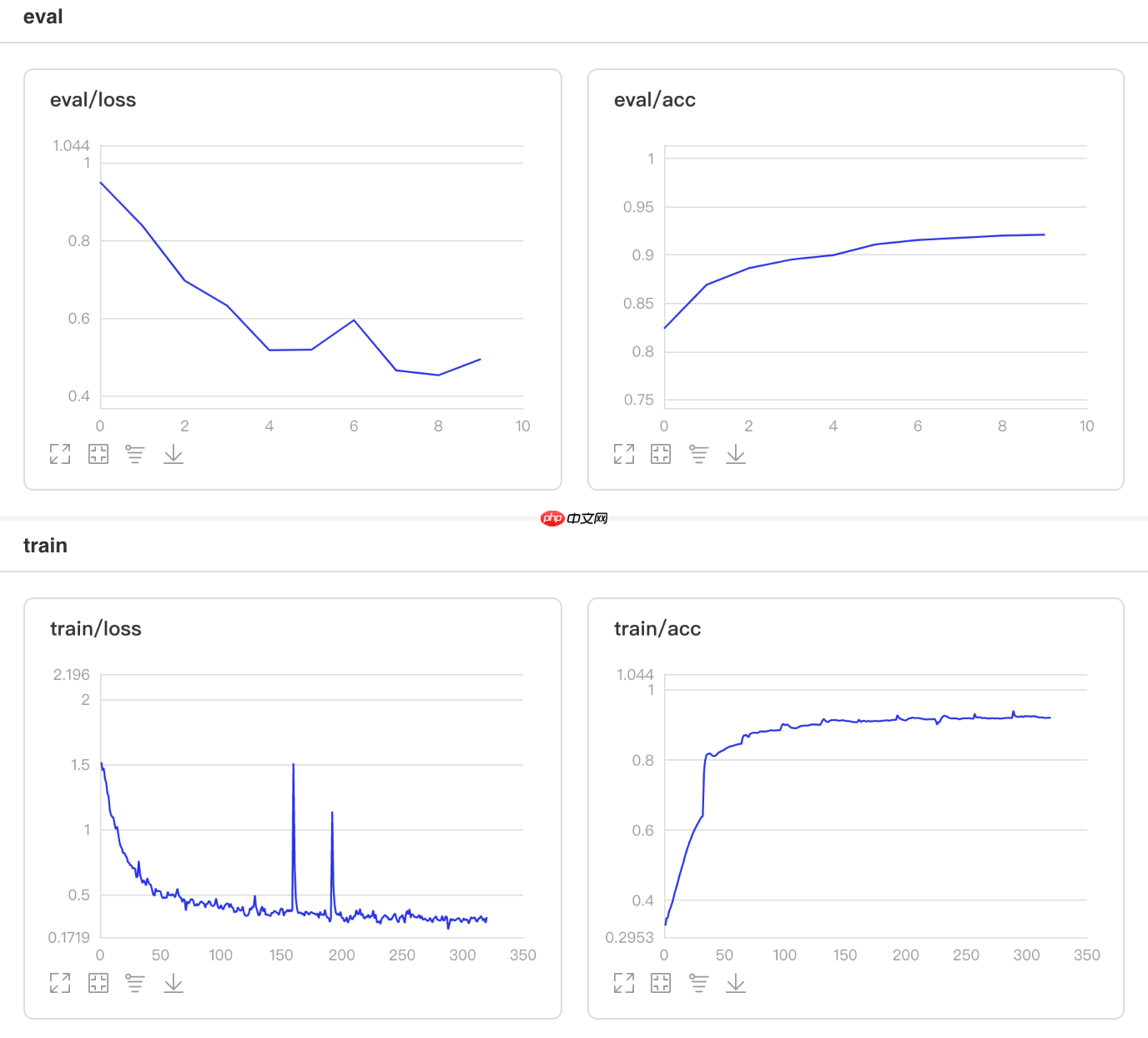
图3 InverseTimeDecay训练验证图 In [10]
## 查看测试集上的效果!python code/test.py --lr 'InverseTimeDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:07:21.973084 3618 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:07:21.977885 3618 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9183 - 729ms/step Eval samples: 1763登录后复制
3.4 使用Lambda衰减学习率
使用方法为:paddle.optimizer.lr.LambdaDecay(learning_rate, lr_lambda, last_epoch=-1, verbose=False)
该接口允许设置Lambda函数以动态调整学习率,由epoch决定,通过此函数乘以初始值可得到新的学习率。
更新公式如下:
lr_lambda = lambda epoch: 0.95 ** epoch登录后复制 In [4]
## 开始训练!python code/train.py --lr 'LambdaDecay'登录后复制
可视化结果
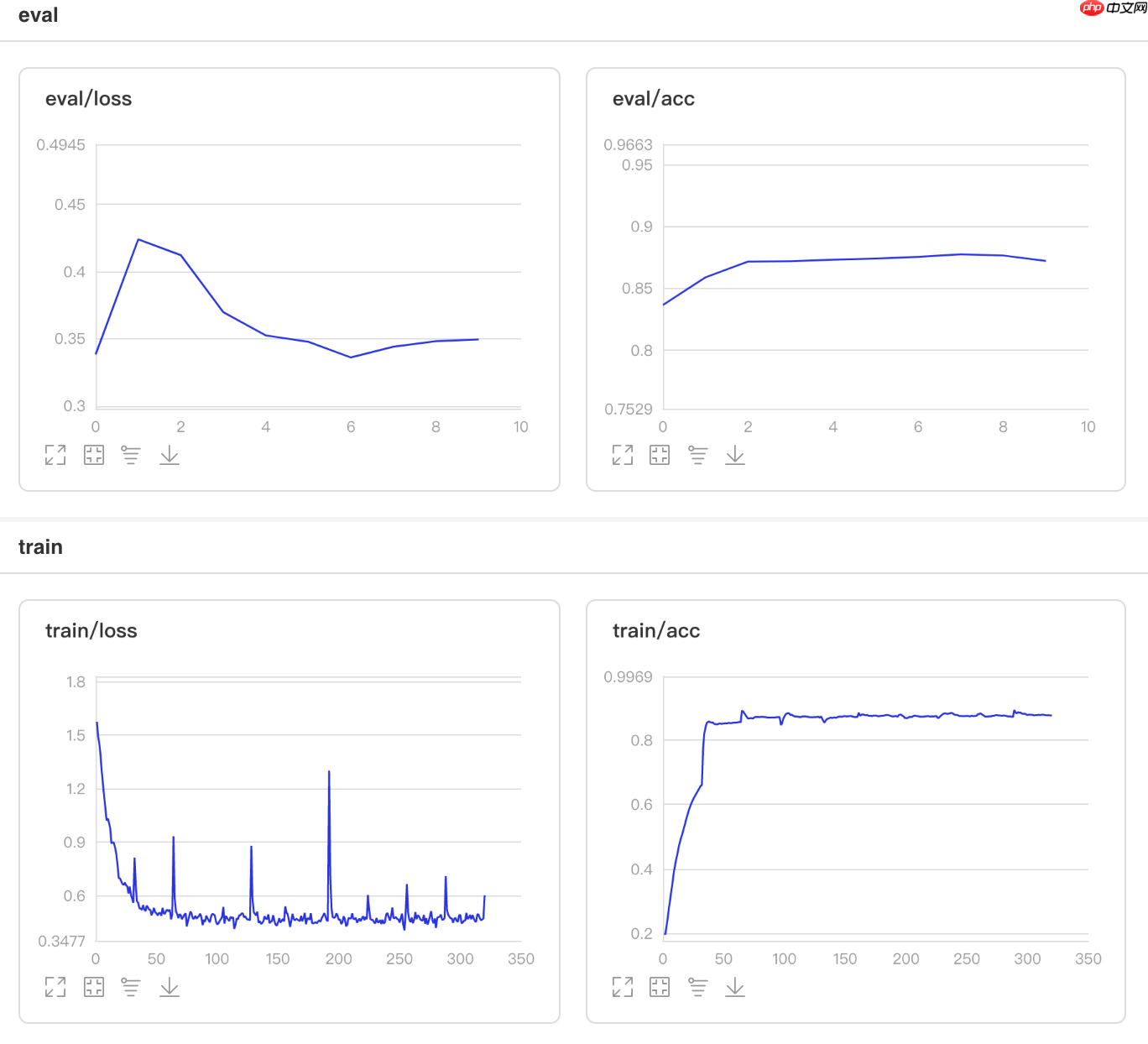
图4 LambdaDecay训练验证图 In [9]
## 查看测试集上的效果!python code/test.py --lr 'LambdaDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:04:35.426102 3249 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:04:35.431219 3249 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.8667 - 731ms/step Eval samples: 1763登录后复制
3.5 使用线性热身学习率
使用方法为:paddle.optimizer.lr.LinearWarmup(learing_rate, warmup_steps, start_lr, end_lr, last_epoch=-1, verbose=False)
- 该接口采用线性学习率热身策略,先缓慢增加学习率,再进行全面的权重更新调整。
热身时,学习率更新公式如下: In [5]
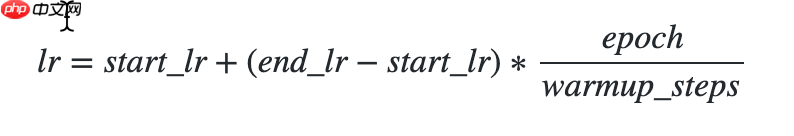
## 开始训练!python code/train.py --lr 'LinearWarmup'登录后复制
可视化结果
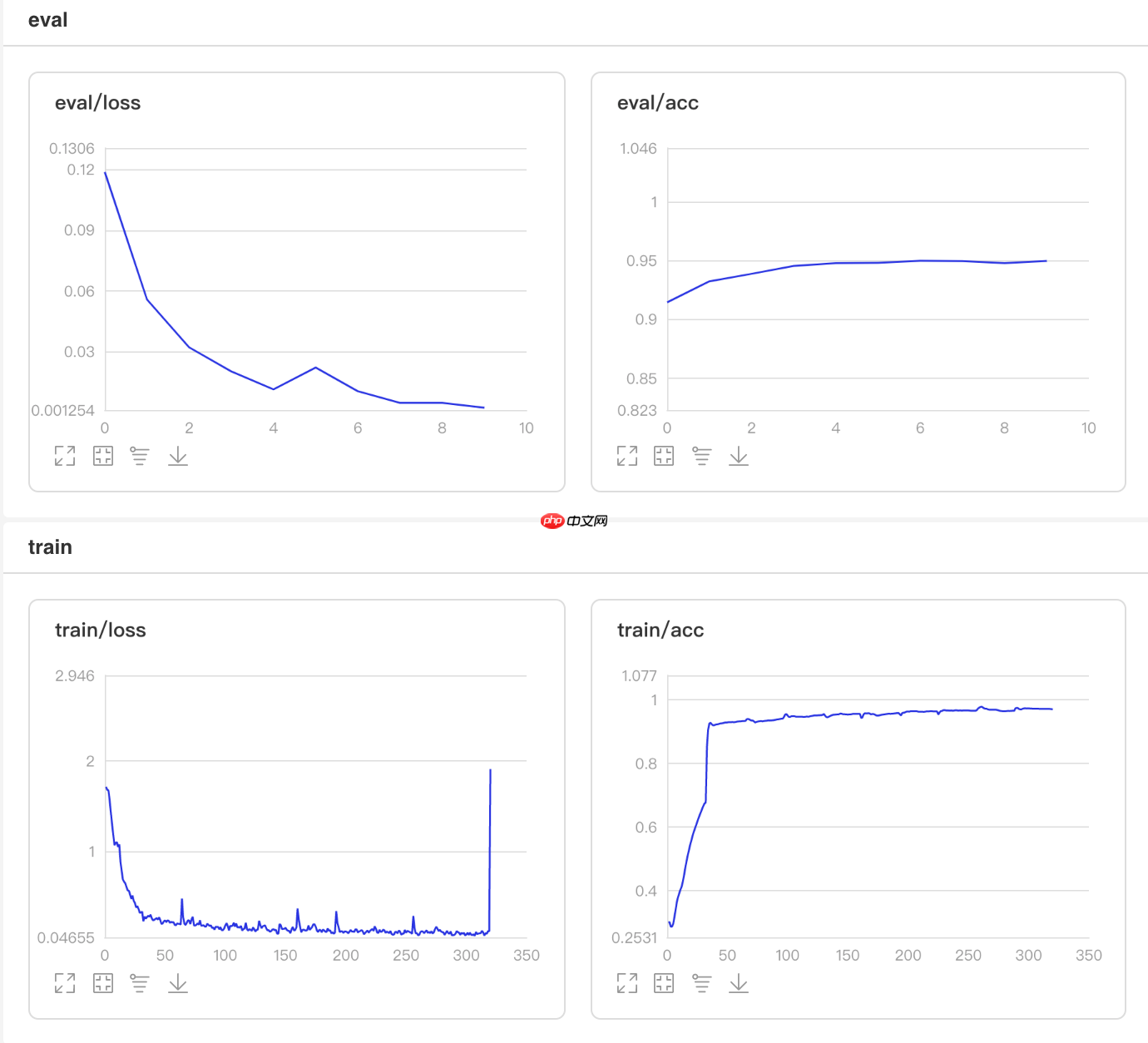
图5 LinearWarmup训练验证图 In [8]
## 查看测试集上的效果!python code/test.py --lr 'LinearWarmup'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:02:36.454607 2972 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:02:36.459585 2972 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9563 - 760ms/step Eval samples: 1763登录后复制
3.6 使用多阶衰减学习率
使用方法为:paddle.optimizer.lr.MultiStepDecay(learning_rate, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
该接口提供一种学习率按指定轮数进行衰减的策略。
学习率更新公式如下: In [6]

## 开始训练!python code/train.py --lr 'MultiStepDecay'登录后复制
可视化结果
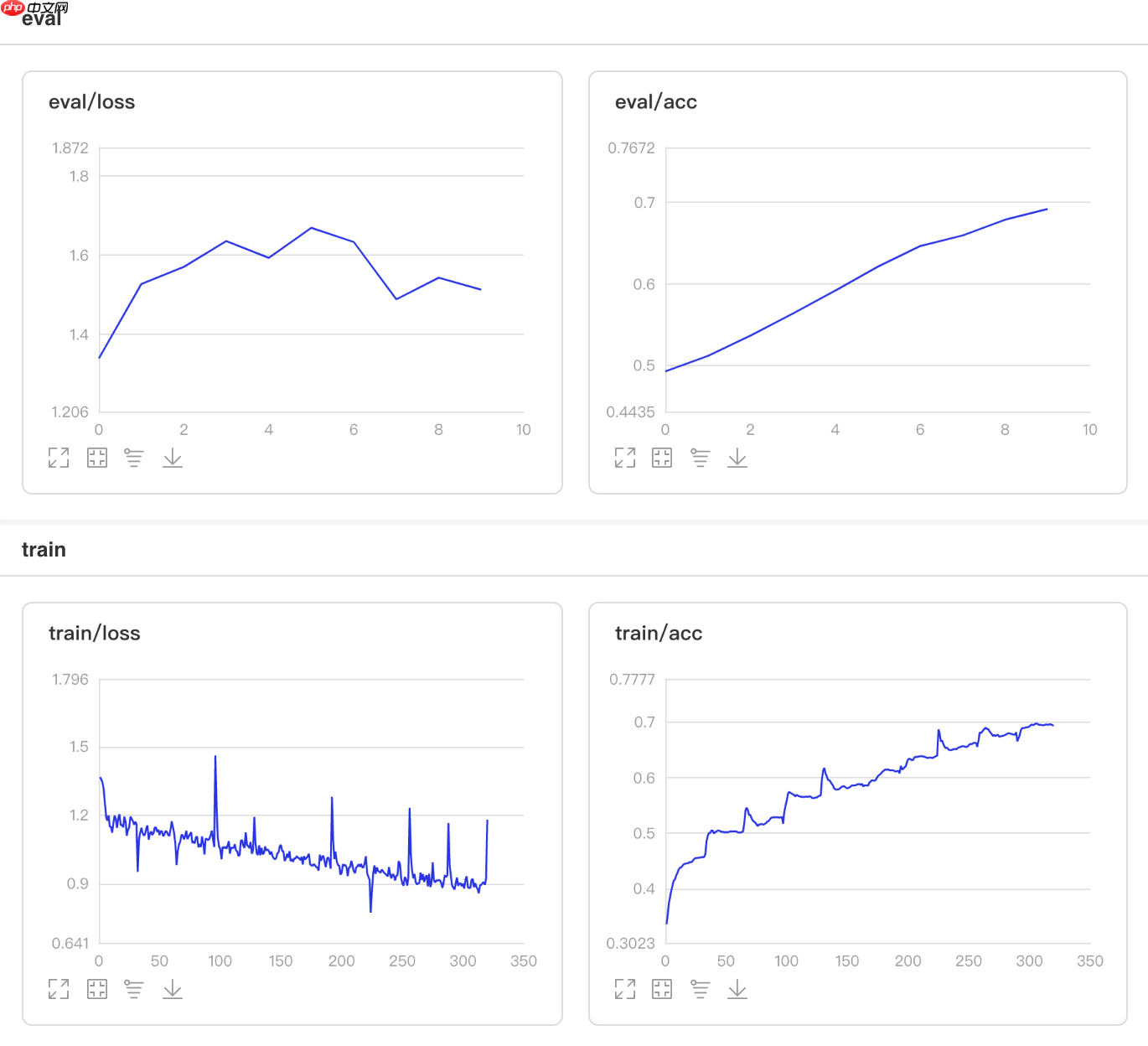
图6 MultiStepDecay训练验证图 In [7]
## 查看测试集上的效果!python code/test.py --lr 'MultiStepDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:59:52.387367 2630 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:59:52.392359 2630 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.6982 - 736ms/step Eval samples: 1763登录后复制
3.7 使用自然指数衰减学习率
使用方法为:paddle.optimizer.lr.NaturalExpDecay(learning_rate, gamma, last_epoch=-1, verbose=False)
该接口提供按自然指数衰减学习率的策略。
学习率更新公式如下: In [7]

## 开始训练!python code/train.py --lr 'NaturalExpDecay'登录后复制
可视化结果
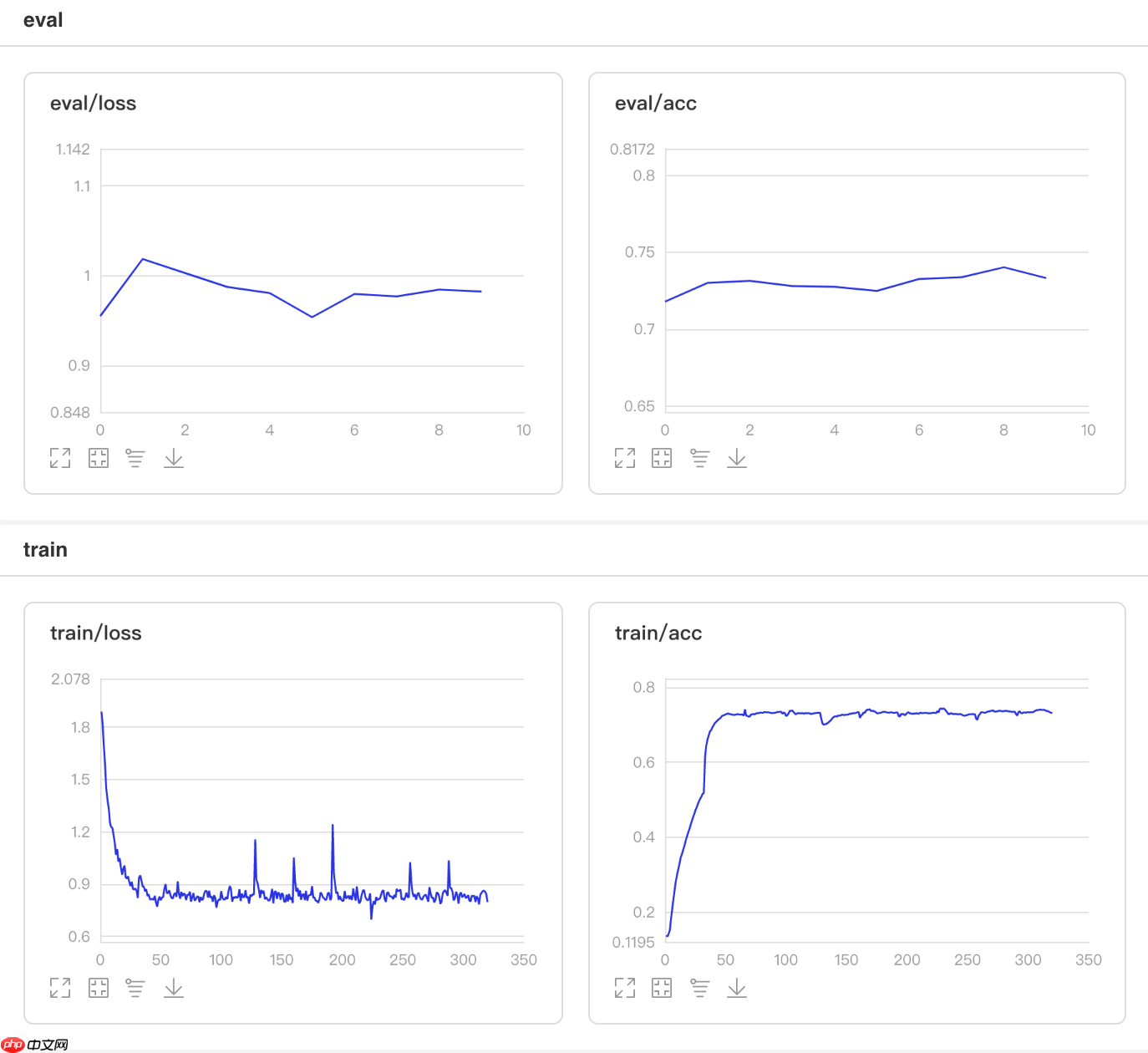
图7 NaturalExpDecay训练验证图 In [6]
## 查看测试集上的效果!python code/test.py --lr 'NaturalExpDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:57:41.858023 2325 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:57:41.863117 2325 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.7379 - 726ms/step Eval samples: 1763登录后复制
3.8 使用Noam衰减学习率
使用方法为:paddle.optimizer.lr.NoamDecay(d_model, warmup_steps, learning_rate=1.0, last_epoch=-1, verbose=False)
该接口提供Noam衰减学习率的策略。
学习率更新公式如下: In [8]
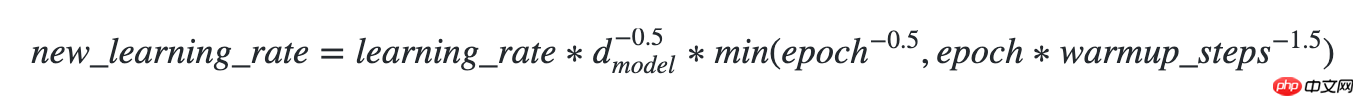
## 开始训练!python code/train.py --lr 'NoamDecay'登录后复制
可视化结果
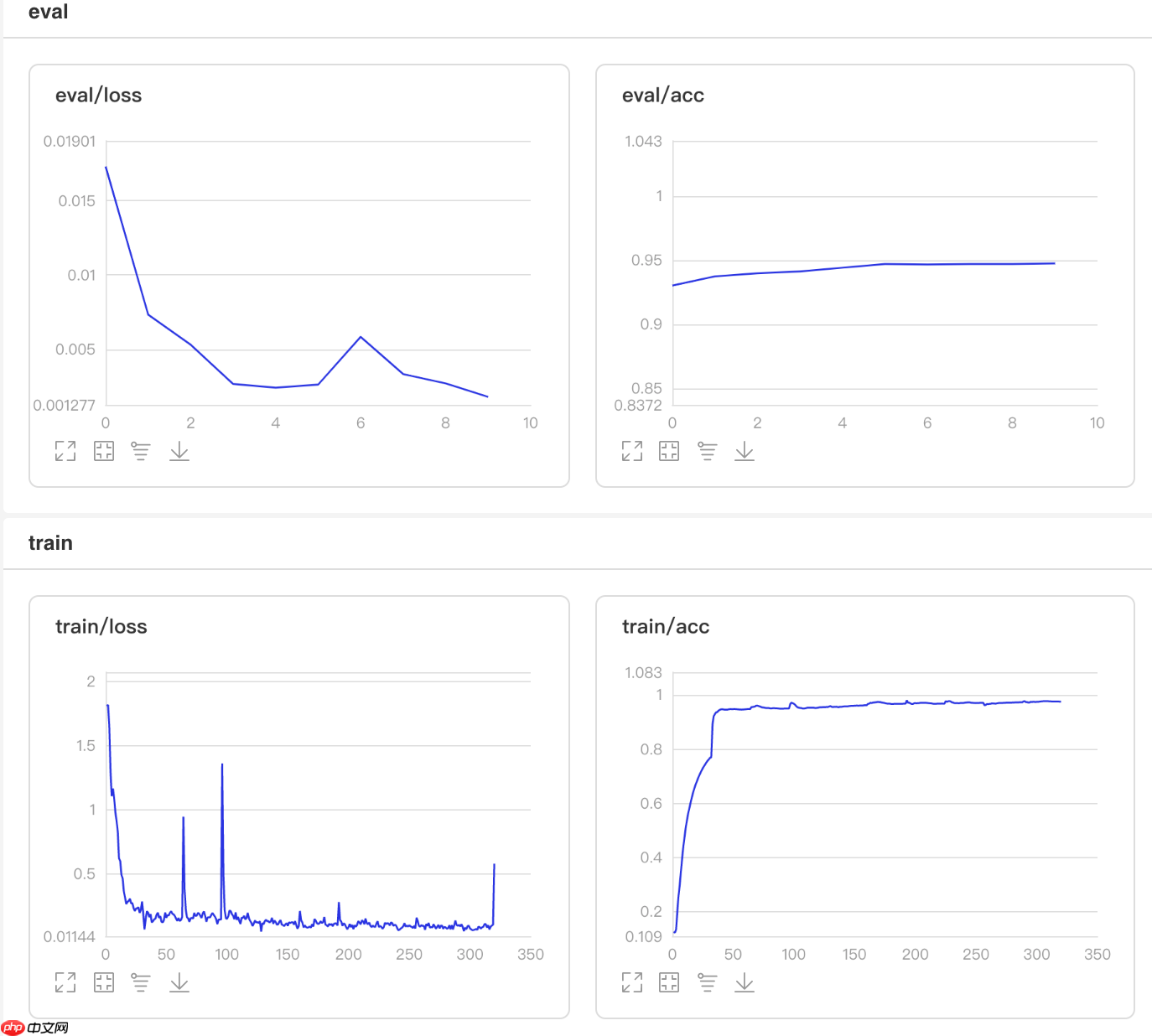
图8 NoamDecay训练验证图 In [5]
## 查看测试集上的效果!python code/test.py --lr 'NoamDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:55:24.339512 1995 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:55:24.344694 1995 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9490 - 749ms/step Eval samples: 1763登录后复制
3.9 使用分段衰减学习率
使用方法为:paddle.optimizer.lr.PiecewiseDecay(boundaries, values, last_epoch=-1, verbose=False)
该接口提供分段设置学习率的策略。 In [9]
## 开始训练!python code/train.py --lr 'PiecewiseDecay'登录后复制
可视化结果
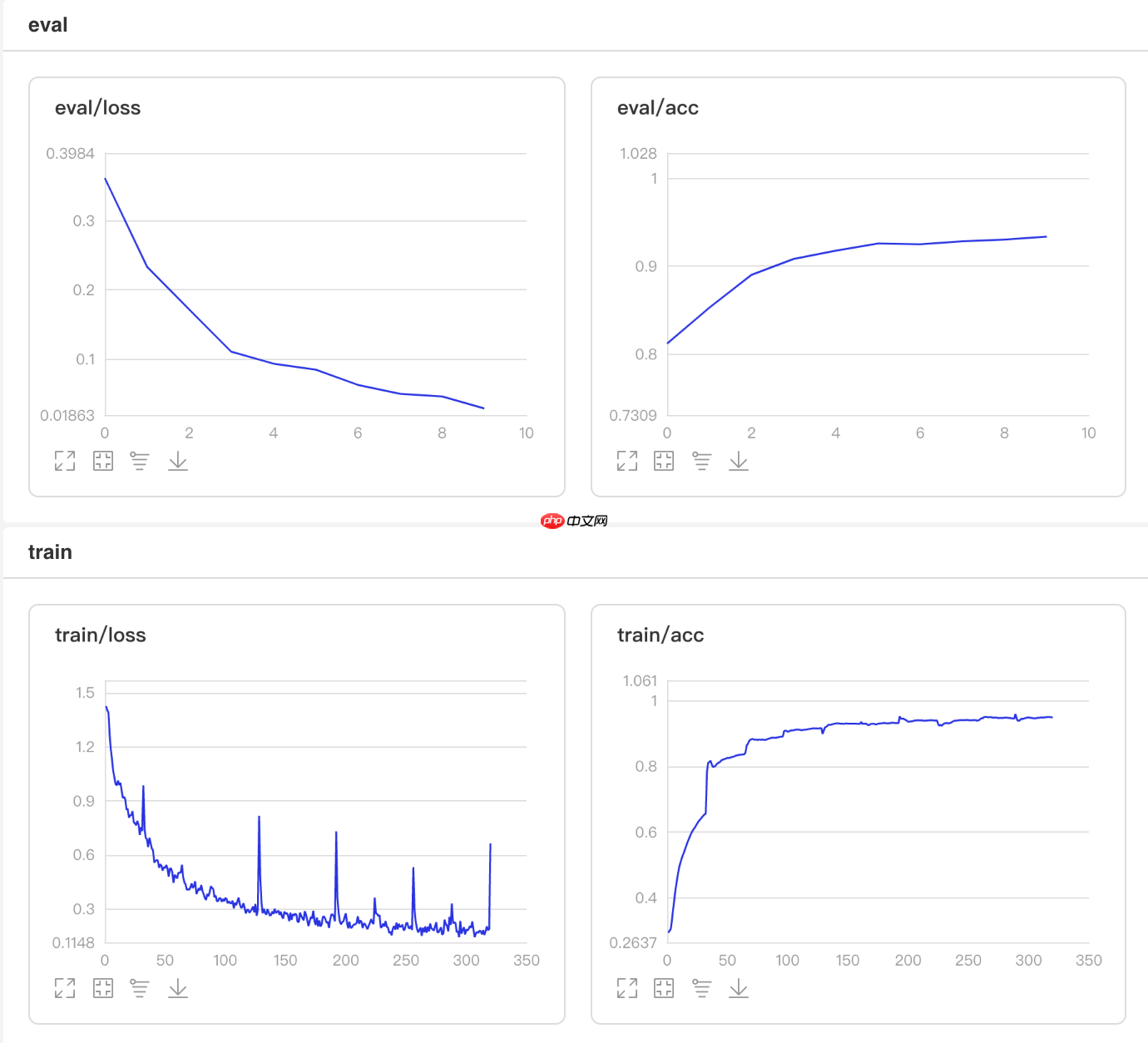
图9 PiecewiseDecay训练验证图 In [4]
## 查看测试集上的效果!python code/test.py --lr 'PiecewiseDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:52:38.228776 1695 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:52:38.233954 1695 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9416 - 749ms/step Eval samples: 1763登录后复制
3.10 使用多项式衰减学习率
使用方法为:paddle.optimizer.lr.PolynomialDecay(learning_rate, decay_steps, end_lr=0.0001, power=1.0, cycle=False, last_epoch=-1, verbose=False)
在本节中,我们介绍了一个新型的学习率策略,利用多项式衰减函数来动态调整学习率。这种策略允许学习率随训练过程逐渐降低,从而提高模型的收敛速度和泛化能力。
## 开始训练!python code/train.py --lr 'PolynomialDecay'登录后复制
可视化结果
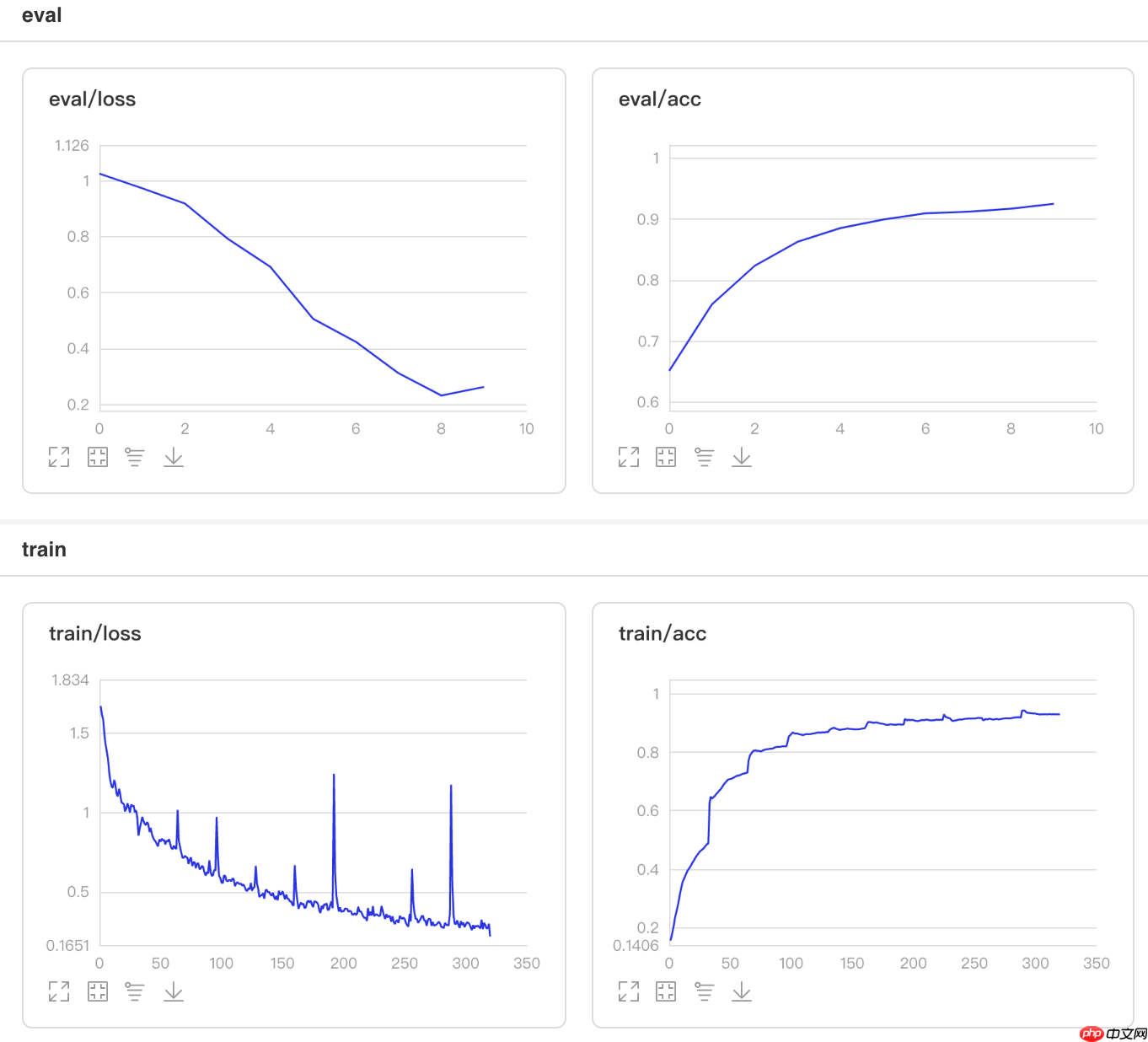
图10 PolynomialDecay训练验证图 In [3]
## 查看测试集上的效果!python code/test.py --lr 'PolynomialDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:50:10.634958 1327 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:50:10.639853 1327 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9325 - 753ms/step Eval samples: 1763登录后复制
3.11 Loss自适应的学习率
使用方法为:paddle.optimizer.lr.ReduceOnPlateau(learning_rate, mode='min', factor=0.1, patience=10, threshold=1e-4, threshold_mode='rel', cooldown=0, min_lr=0, epsilon=1e-8, verbose=False)
该接口采用Loss自适应学习率策略。一旦损失值连续停滞降不下超过patience个epoch,学习率将会降低至初始学习率factor的相应比例。每次降低的学习率后,系统将进入cooldown个epoch的冷静期,在此期间不会监控loss的变化或调整学习率。冷静期结束后,系统将继续监测loss的变动。
## 开始训练!python code/train_reduceonplateau.py登录后复制
可视化结果
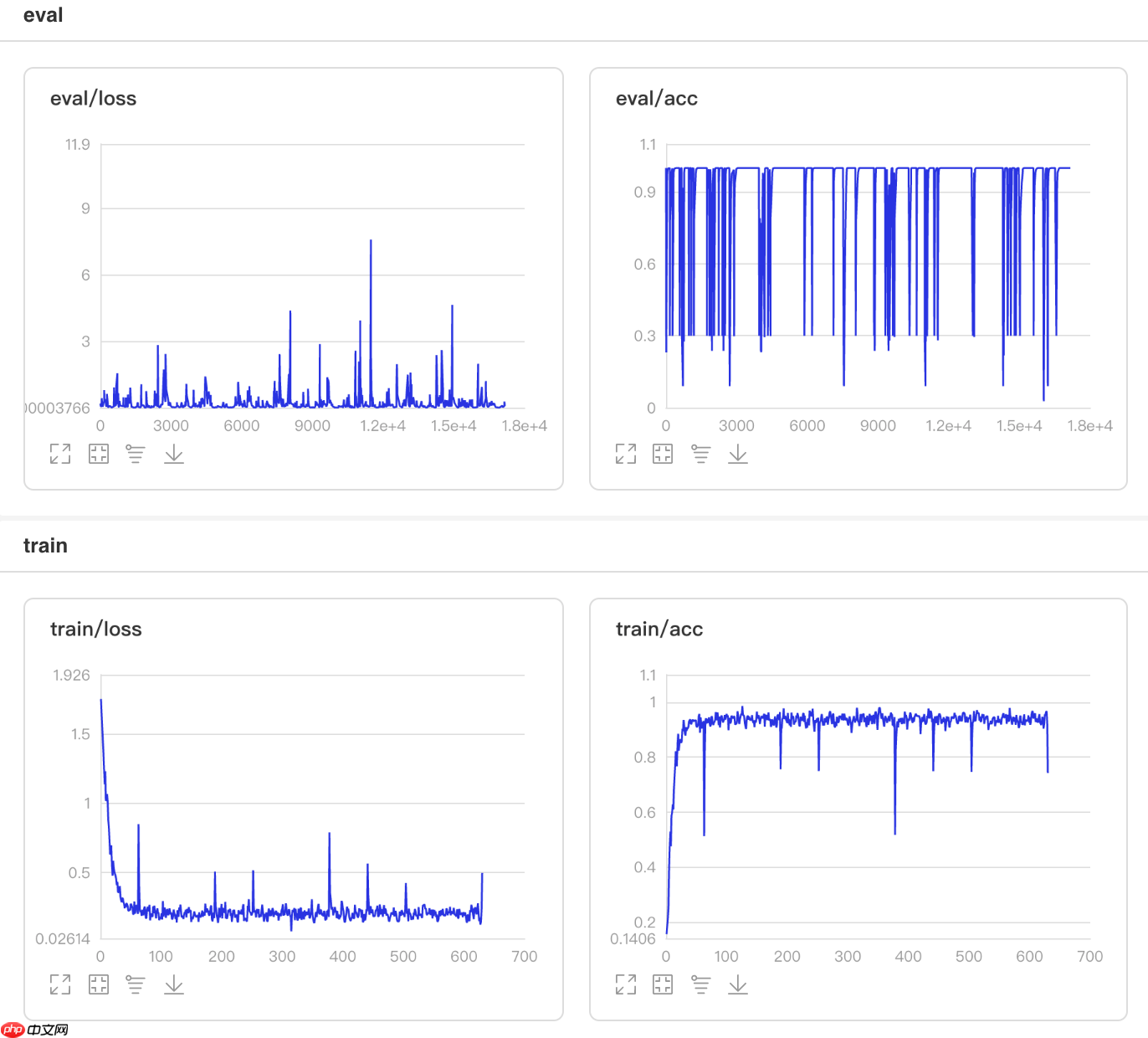
图11 ReduceOnPlateau训练验证图 In [22]
## 查看测试集上的效果!python code/test.py --lr 'ReduceOnPlateau'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 00:26:51.685511 20016 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0508 00:26:51.690647 20016 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9365 - 706ms/step Eval samples: 1763登录后复制
3.12 阶段衰减学习率
使用方法为:paddle.optimizer.lr.StepDecay(learning_rate, step_size, gamma=0.1, last_epoch=-1, verbose=False)
该接口提供一种学习率按指定间隔轮数衰减的策略。 In [12]
## 开始训练!python code/train.py --lr 'StepDecay'登录后复制
可视化结果
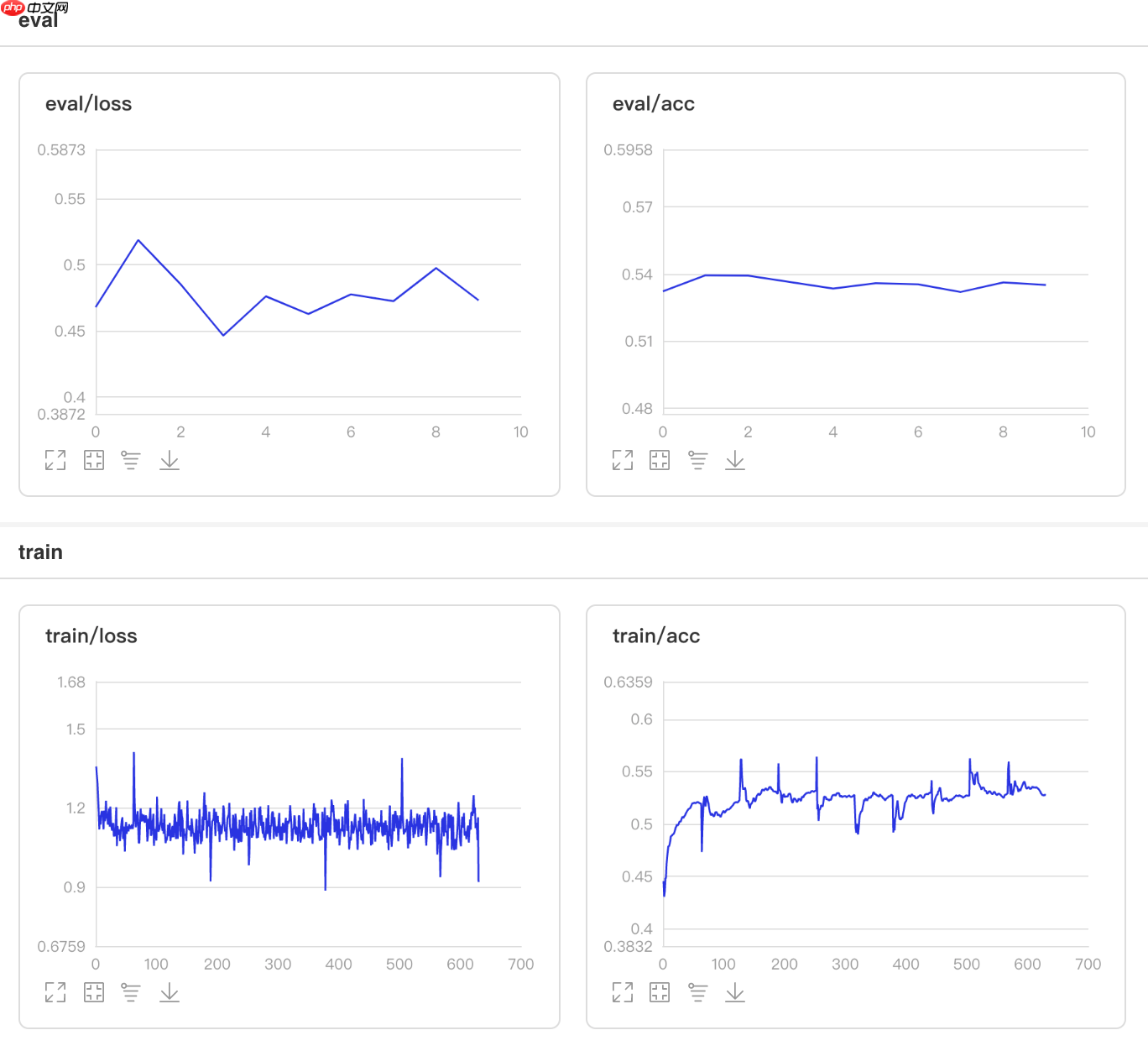
图12 StepDecay训练验证图 In []
## 查看测试集上的效果!python code/test.py --lr 'StepDecay'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0507 23:30:52.671571 14817 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0507 23:30:52.676681 14817 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.5315 - 733ms/step Eval samples: 1763登录后复制
4. 自定义学习率算法
自定义学习率不仅限于使用Paddle供的LR算法基类,还可以完全不依赖它,而是采用自定义方式来实现循环学习率算法CLR和每固定周期调整学习率的Adjust_lr。这种灵活性使得我们能够根据具体任务灵活设计学习速率策略。
4.1 自定义学习率算法CLR
CLR方法来自于论文Cyclical Learning Rates for Training Neural Networks
根据论文所述,CLR能在训练时周期性调整学习率,使优化器保持在最优点附近。
更新公式如下: In [13]

## 开始训练!python code/train_clr.py登录后复制
可视化结果
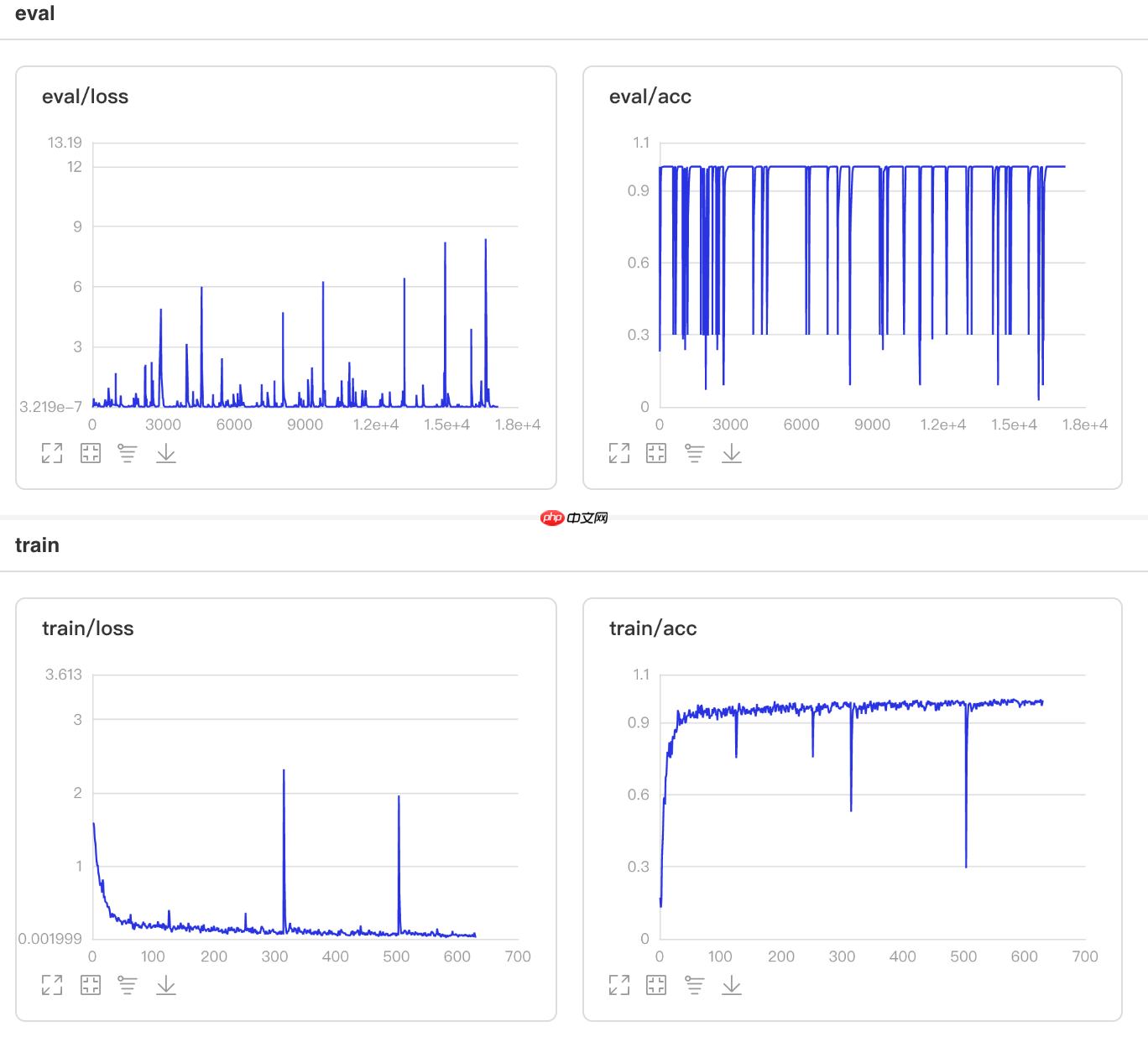
图13 CLR训练验证图 In [1]
## 查看测试集上的效果!python code/test.py --lr 'clr'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:37:39.301434 105 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:37:39.306394 105 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9575 - 731ms/step Eval samples: 1763登录后复制
4.2 自定义学习率算法Adjust_lr
为了调整学习率,在整个epoch内,每两个epoch会将其衰减到原始值的。
## 开始训练!python code/train.py --lr 'Adjust_lr'登录后复制
可视化结果
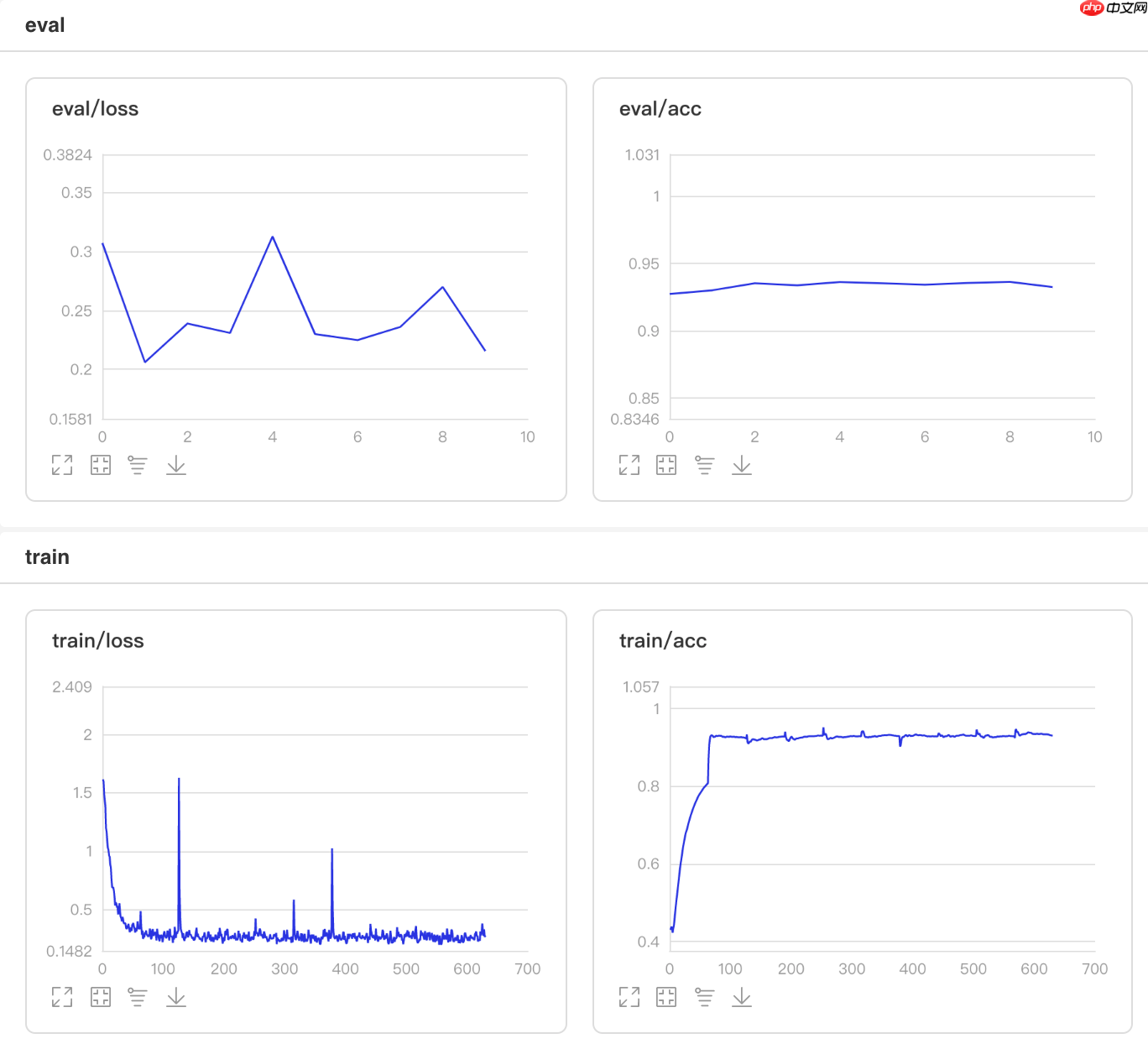
图14 Adjust_lr训练验证图 In [2]
## 查看测试集上的效果!python code/test.py --lr 'Adjust_lr'登录后复制
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0511 21:55:19.051586 6496 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0511 21:55:19.055864 6496 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9308 - 713ms/step Eval samples: 1763登录后复制
5. 结果比较
在本项目中,学习率的性能表现见下图:自定义的循环学习率CLR最优,推荐使用;其次为线性启动、Noam衰减、余弦退火和部分递减。
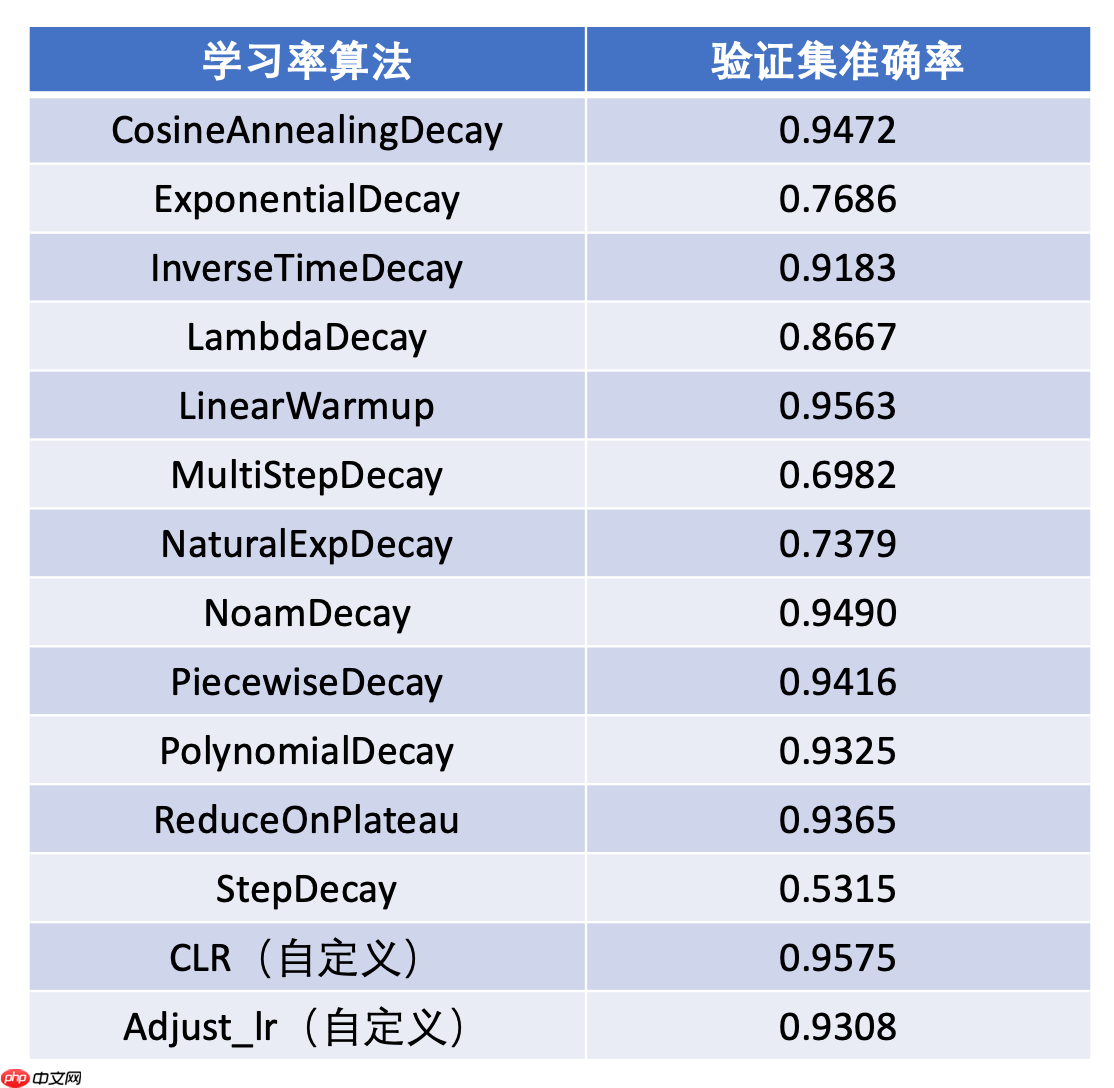
图14 学习率性能比较
以上就是一文搞懂Paddle2.0中的学习率的详细内容,更多请关注其它相关文章!